

LSM Tree and heavy storage engines
A database system is built by gluing together multiple pieces of technology. One such piece is a storage engine which is responsible for providing an abstraction over how the data is written and retrieved from the underlying hardware. Whenever we think about the internals of storage engines, a data structure that overpowers the discussion is a B-Tree. Although a large chunk of mainstream database solutions uses B-Tree, a separate class of databases have proven their mettle by leveraging a separate data structure for storage. These databases primarily cater to use cases where fast writing is an essential part of their requirement. The underlying data structure these databases use is called Log(L) Structured(S) Merge(M) tree(Or LSM tree for short).
LSM Tree faster than B-Tree for write operations
So, in case of a typical B-Tree, any form of an update results in accessing random nodes in the tree for the update due to the balancing operation of the tree. This can turn into a bottleneck when the storage system is experiencing heavy write traffic. LSM tree takes a different path for storing data. Let us investigate how LSM tree does this:
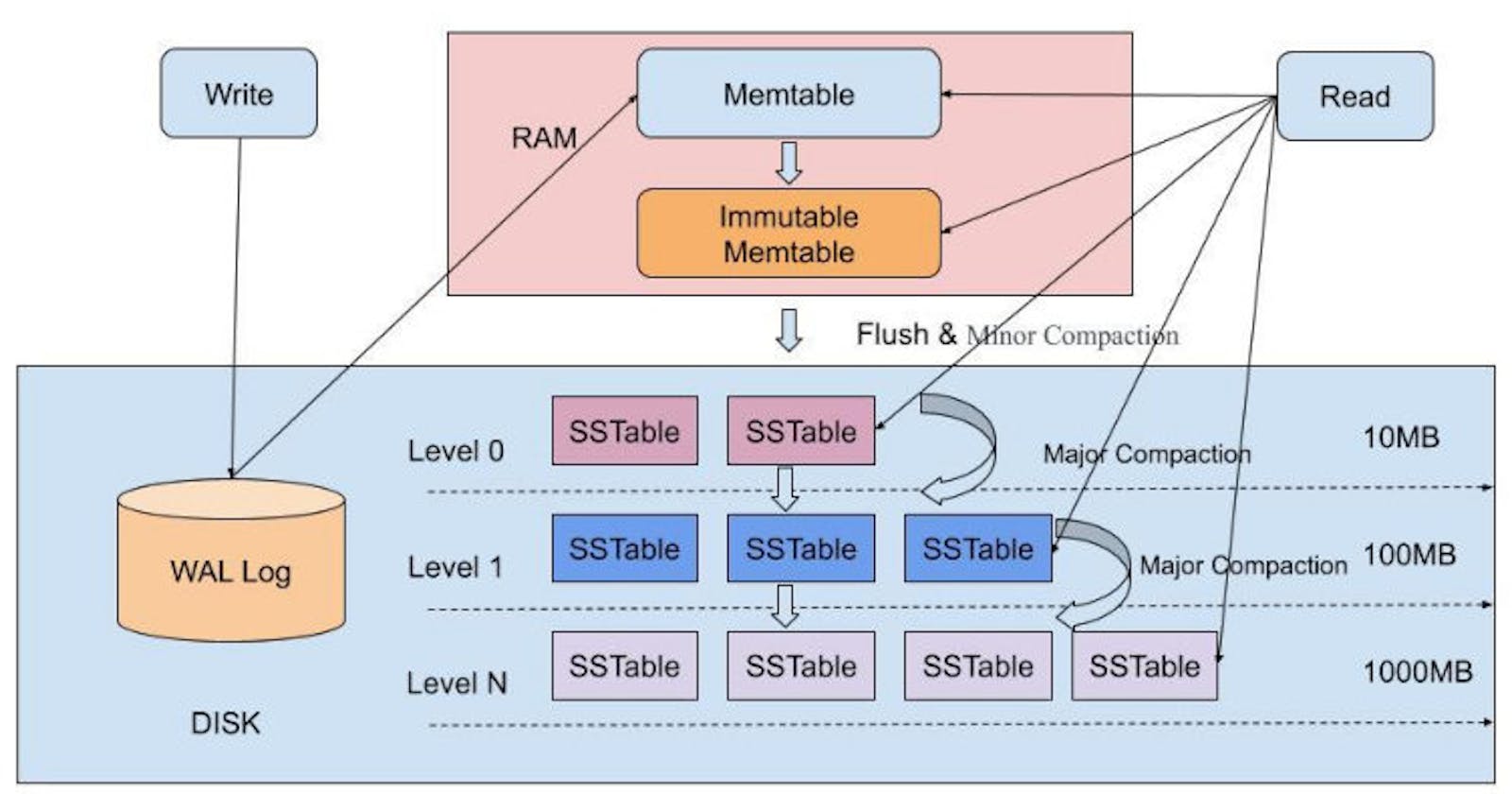
All the writes are initially persisted into an in-memory sorted data structure(Known as Memtable). The sorting property typically comes from an AVL-tree implementation.
Once the Memtable reaches a threshold memory, it is converted into an immutable data structure known as SSTable(Short for sorted string table) and flushed to disk. The original Memtable is cleared after this and allocated with new memory.
If a key is deleted, it is assigned a tombstone value(It can be a unique value that distinguishes the tombstone from other user assigned values for the key).
From time to time, a background job takes care of merging the on-disk SSTables in order to compress the overlapping keys. For example, the current SSTable has an entry of SET A 2, whereas a previous SSTable has an entry of SET A 4 then we can merge these two entries and just keep SET A 2. This process is known as compaction.
On the other hand, an update on B-Tree results in multiple updates happening as part of balancing the original tree. These updates happen on disk that will result in multiple disk hops affecting the latency of write operation. Whereas in case of LSM tree, an update just results in appending a log to an in-memory store so it comparatively faster than a B-Tree.
Reading data in a LSM Tree
There ain’t no such thing as a free lunch. Especially not in software systems. There are usually trade-offs. The performance enhancement for write operations that comes along with LSM tree ends up getting traded for read performance. Let us look at how an LSM tree performs a read operation and why it ends up being slower than a B-Tree for read operations:
For reading the value associated with a key, we first investigate the in-memory Memtable. If the value is updated recently, then there is a high chance that we can find it in-memory and we can avoid interacting with the disk. This case is efficient in terms of latency.
If we are unable to find the key in Memtable, we start reading it from the SSTables on disk in decreasing order of creation time. So, the latest created disk is queried first, then the second latest and so on. If our compaction algorithm is efficient, then there is a high chance that we might be able to find the key in the top few SSTables.
If the key is deleted then we will find a tombstone associated with the key and we can return a KEY_NOT_FOUND exception.
But what happens if the key was never written in our system. This ends up becoming the worst case as we will end up reading all the SSTables on the disk in order to determine that the key is not present.
There are some optimizations which can be done in order to avoid the worst-case lookup of non-existent key such as a Bloom Filter. To improve read performance, we can also maintain an index file on disk which contains the mapping of keys to the id of latest on-disk segment they are written to. Now when we are unable to find the key in Memtable, we can read the latest segment id from index file and directly read the given segment. This requires only two disk hops and prevents us from reading all the segments on the disk. But all these optimizations come with their own challenges and maintenance costs.
Now if we compare this with read performance of B-Tree, we will need to query at most till the depth of tree which is logarithmic time complexity for a balanced tree. Hence the read-amplification(amount of work done per read operation) of LSM tree tends to be higher than a B-Tree unless we perform some additional optimizations.
DynamoDB uses B-Tree, not LSM Tree. But, that DynamoDB may diverge from the original Dynamo paper.
Mainstream databases using LSM tree
Multiple mainstream databases have started adopting LSM tree for their storage layer. Cassandra is one of such well known databases that uses LSM tree over a B-Tree. HBase is another such mainstream technology that leverages LSM tree. One of the well-known implementations of LSM tree is LevelDB created by Google and RockDB which is an extension of LevelDB and is created at Facebook.
NOTE: There are various enhancements coming into the space of LSM tree and it is an area that shows potential for various innovations in the space of storage technologies. With improvements in the underlying storage hardware such as SSDs, there are innovations being done to improve the read amplifications of LSM tree.