

Quick intro
First, we must know what is the role of the customer profile teams? . The customer profile is the account-metadata of any customer in systems that try to recommend products or food to the user.
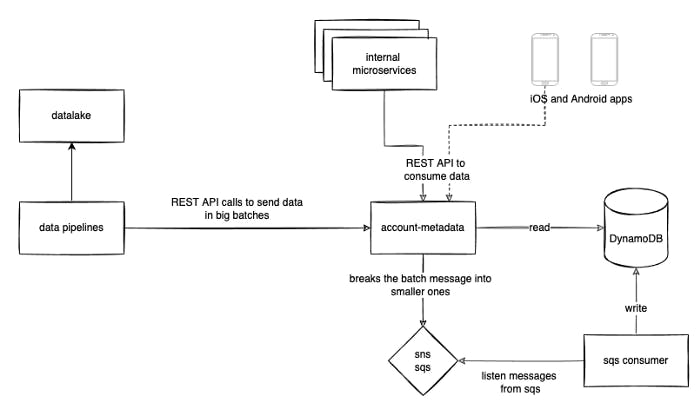
Let's imagine that we have a microservice that stores customer metadata (internally we call it account-metadata) and during peak hours it reaches over 2 million requests per minute. This system is called by the web and mobile apps and by many internal teams to fetch customers’ data. The data is stored into a single DynamoDB table (with 1.3 billion items using 757,3GB) with DAX as DynamoDB cache and the new batches of data is going to post into SNS/SQS that will be consumed by another part of the application that then will validate the item and if it’s ok, save it on Dynamo. With this approach, the endpoint that receives the batch of items can answer fast and we can make the write without relying on the HTTP connection (this is quite important because the communication with Dynamo may fail and try it again could make the HTTP response time slow). Another benefit is that we can control how fast/slow we want to read the data from SQS and write it on Dynamo by controlling the consumers.
What kind of data do we store there? Features of each customer. Some examples of features:
- a counter of the total of orders
- the top 3 favorite products/dishes
- favorite product types/restaurants
- in which segmentation the user is
This is the architecture that we have imagined:
Main Problem
The pipeline of the data team, to export the data from data lake, process it using Databricks and Airflow, and then finally send it to account-metadata, consists of lots of steps and could fail very easily. Often something fails along the way, we do not always have the best monitoring of every single piece. Which means that it is not reliable. This is a big problem for the Customer Profile team, given that the quality of our data is at the core of their concerns and interest.
So, we started to look around and think about how we can change that part of the infrastructure. Which means, to change the ingestion of hundreds of millions of records per day.
ML Magic
ML devs built an awesome tool called Feature Store (FS). In summary, Feature Store is a way to provide and share data very easily to empower ML applications, model training, and real-time predictions. On one side, FS reads data from somewhere (data lake, data warehouse, Kafka topics, etc), aggregates it, does processing or calculation, and then exports the results on the other side (API, in some database, Kafka topics, etc).
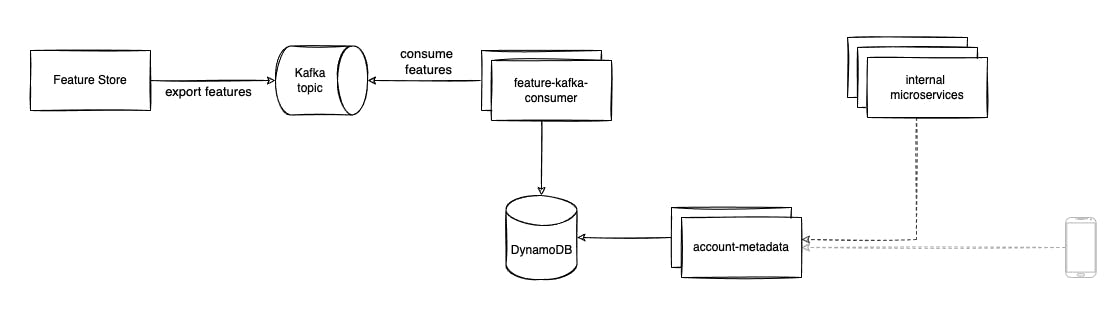
So, it became clear that was pretty much what we needed: a centralized, unique, and very organized way to consume data from the data lake. Even though we would be using the FS for something that’s not really related to ML applications, that would be a very suitable use case for us. It would make things much easier for us: FS would export the data somehow, then we’d just need to save it on our database. We would change the super complex, and very fragile pipeline, to a robust and solid mechanism. So, we decided that we would export the features to the endpoint via a Kafka topic.
However, the FS was not able to export the features in batches, which means that to each customer (around 60 million) and to each feature, a message would be exported. At that time, Let's say that we had around 40. That means 60mi * 40 = 2.4 billion messages per day, but probably growing that number to over ~2.6bi a few months later.
So, we should be able to consume ~2.6bi Kafka messages per day.
Consuming data from FS
Let's define our database schema to make the explanation simpler. We need to divide the account-metadata into different contexts. Let's call it namespace (As the sorting key) and account_id as the partition key. Also, we need to define the feature details and the timestamp. So, the schema would be like this:
{
account_id: string
feature_name: string
feature_value: string
namespace: string
timestamp: int
}
With that, we could create a consumer that would listen to the Kafka topic and save the features in the DynamoDB table.
That’s how our table looks like:
| account_id | namespace | columns and its values… |
| 283a385e-8822–4e6e-a694-eafe62ea3efb | orders | total_orders: 3 | total_orders_lunch: 2 |
| c26d796a-38f9–481f-87eb-283e9254530f | rewards | segmentation: A |
That’s the new architecture:
In Practice
If we tried to implement our consumer using Java. It would perform quite well, but very far from what we needed: 4k features consumed per second per pod/consumer. Even with some tweaks and different configuration, it was still far away from the 2.6 bi. Also, if we tried to implement it using C#. It would be far away as well with 5.3K Feature consumed per second per pod/consumer.
if we tried to implement it with Go using goka, a high level Go lib to interact with Kafka. It would be way better: 8.5k features consumed per second per pod/consumer. However, it was still quite far from what we needed. but with sarama, we’re able to implement a worker to consume 1 million events per minute (20k features consumed per second per pod/consumer.). Each pod/consumer creates three goroutines to process the messages received from Kafka. And yes, we did it!
Now, we are processing over 1 million events per minute resulted in a lot of writes operations in DynamoDB. At first, the database would suffer quite a bit, so we had to scale it to handle the write requests.
Testing
We could test the approach using a hardcoded namespace. e.g., namespace: testing-order instead of namespace: order. Then, Compare the values between the namespaces to ensure that they are the same.
Optimization
The database costs were high, and this approach was quite ineffective because we’re doing one write per message to DynamoDB even though we had a couple of messages from the same account_id quite closely in the Kafka topic, given that we’re using the account_id as the key partition. Something like this:
| account_id | feature_name | feature_value | namespace | timestamp|
| user1 | total_orders | 3 | orders | ts1 |
| user1 | total_orders_lunch | 1 | orders | ts3 |
| user1 | segmentation | foo | rewards | ts2 |
| user2 | segmentation | foo | rewards | ts2 |
As you can see, the first two records are from the same user and to the same namespace. With the account_id as the key partition, the events from the same account_id would be consumed by the same consumer. With that, we could create a kind of in-memory buffer to aggregate and put the events of the same account_id and namespace together and write them once in DynamoDB.
Also, we should change the Kafka consumer to fetch data from the topic in batch, increasing the number of bytes “per fetch”, resulting in a greater number of messages. Instead of getting and processing one message at a time, we fetch 1000 messages, create a map where the key is the account_id and the value is a list of features, and makes one save in Dynamo per account_id in the map. With that, we decreased the number of operations in Dynamo by 4 times.
NOTE: It was easy to mark one message as “processed” and commit it. However, while processing one thousand of them, it is not that easy to mark them as read and commit if in the middle of processing a couple of messages in this batch fails. We had to be more careful with the part of the code.
Monitoring
Monitoring the system isn't an easy mission to do. But We can use a lot of Prometheus/Grafana to create custom metrics for the consumers and get metrics of the pods. Datadog to collect metrics from the Kafka topic and created dashboards about the consumer group and collect metrics of the cluster.
NOTE: It does require some tunning to make the Kafka consumers very fast. The main piece of advice is to read the documentation carefully and play around with the parameters. The main ones are “fetch.min.bytes”, “auto commiting” and “setting max intervals”.
The customer profile teams are so amazing and brilliant. They are facing great challenges and conquering them in brilliant way! This was just a small part of their amazing day.
References
- pkg.go.dev/github.com/lovoo/goka
- go.dev/tour/concurrency/1
- pkg.go.dev/github.com/shopify/sarama
- en.wikipedia.org/wiki/Prometheus_(software)
- en.wikipedia.org/wiki/Grafana
- en.wikipedia.org/wiki/Datadog
- en.wikipedia.org/wiki/Apache_Kafka
- aws.amazon.com/blogs/aws/queues-and-notific..
- aws.amazon.com/getting-started/hands-on/pur..
- amazonaws.cn/en/dynamodb/dax
- docs.amazonaws.cn/en_us/amazondynamodb/late..
- docs.databricks.com
- airflow.apache.org/docs/apache-airflow/stable