


PermalinkIntroduction
In this article, I’d like to share my experience in distributed microservices architectures, especially regarding data consistency.
PermalinkProblem Definition
Data consistency is the hardest part of the microservices architecture. Because in a traditional monolith application, a shared relational database handles data consistency. In a microservices architecture, each microservice has its own data store if you are using a database per service pattern. So databases are distributed among the applications.
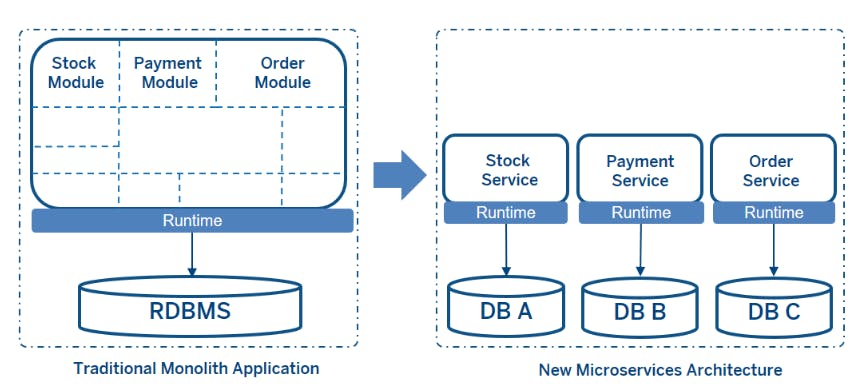
Any microservice architecture must have ACID transactions. The acronym ACID means:
- Atomicity: all the steps of a transaction is succeeded or failed together, no partial state, all or nothing
- Consistency: all data in the database is consistent at the end of transaction
- Isolation: only one transaction can touch the data in the same time, other transactions wait until completion of the working transaction
- Durability: data is persisted in the database at the end of the transaction
In order to achieve strong consistency in monolith application, you need to do one unit of work at time.
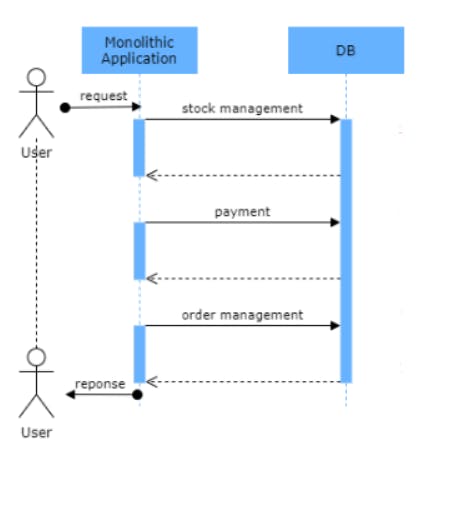
In the other hand Microservice architecture has no center database and no single unit of work. Now, Business logic is splitted into multiple transactions. Let's take an example.
When we open Amazon.com to buy any product, We know that the products we are seeing right now are available to buy. So, We go and click on the product that we want, Right. So, What if Amazon.com says that There is an error because this product isn't available!. This will make a bad user experience because It doesn't make sense to put a product on the site and It isn't available to buy!.
In this scenario, We have three problems because of the consistency which are reliability, function correctness and bad user experience.
- Reliability: What if the server that made the last transaction on this product shut down. Who will update the database?
- Function correctness: The availability of an unavailable product!
- user experience: The user didn't get what he wanted.
PermalinkPossible Solutions
First of all, there is no single solution which works well for every case. Different solutions can be applied depending on the use-case.
There are two main approaches for inconsistency.
- Strong consistency
- Eventual consistency
PermalinkStrong consistency
Transactions are executed on two or more resources (e.g. databases, message queues). Data integrity is guaranteed across multiple databases by a distributed transaction manager or coordinator.
Strong consistency is a very complex process since multiple resources are involved in the process.
So, The main idea behind it is to have a coordinator that updates this data across all databases.
PermalinkPros
- Function correctness
- Great user experience
- Support ACID features
PermalinkCons
- Very complex process to maintain
- High latency & low throughput since it is a blocking process (not suitable for high load scenarios)
- Possible deadlocks between transactions
- No reliability because transaction coordinator is a single point of failure
NOTE: for the single point of failure. There are some algorithms that try to solve this issue e.g. Epidemic, Gossip etc. We aren't going to cover those algorithms in this article.
PermalinkEventual Consistency
Eventual consistency is a model used in distributed systems to achieve high availability. In an eventual consistent system, inconsistencies are allowed for a short time until solving the problem of distributed data.
Eventual consistency doesn't use ACID, It uses BASE database model.
While ACID provides a consistent system, BASE model provides high availability.
The acronym BASE means:
- Basically Available: ensures availability of data by replicating it across the nodes of the database cluster
- Soft-state: due to lock of the strong consistency data may change over the time. Consistency responsibility is delegated to the developers
- Eventual consistency: immediate consistency may not possible with BASE but consistency will be provided eventually (in a short time)
There are a lot of patterns that achieve eventual consistency. We are going to cover the most two popular patterns.
- Saga pattern
- Event-first pattern
PermalinkSaga pattern
A saga is a sequence of local transactions. Each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails because it violates a business rule then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.
There are two ways of coordination sagas:
- Choreography
- Orchestration
PermalinkChoreography
Each local transaction publishes domain events that trigger local transactions in other services. So, this means that no central coordinator exists in this case. Each service produces an event after completion of its task and each service listens to events to take an action. It uses event sourcing.
Event sourcing is an approach to store the state of event changes by using an Event Store. Event Store is a message broker acting as an event database. States are reconstructed by replaying the events from the Event Store.
Choreography can work well for a small number of steps in a transaction. When the number of steps in a transaction is increasing, it is difficult to track which services listen to which events.
PermalinkOrchestration
An orchestrator (object) tells the participants what local transactions to execute. Now, The coordinator is responsible for sequencing transactions according to business logic. Orchestrator decides which operation should be performed. If an operation fails, the Orchestrator would undo the previous steps. It is called a compensation operation. Compensations are the actions to apply when a failure happens to keep the system in consistent state and they must be idempotent-Isolated because they might be called more than once within the retry mechanism.
NOTE: Undoing changes may not be possible already when data has been changed by a different transaction.
PermalinkPros
- Non-blocking operations running on local atomic transactions
- No deadlocks between transactions
- No single point of failure
PermalinkCons
- Does not have read isolation, needs extra effort (e.g. the user could see the operation being completed, but in a few seconds, it is cancelled due to a compensation transaction.)
- Difficult to debug, when participant service count is increased
- Complex
PermalinkEvent-First Pattern
The idea is to make the event that has been triggered to update the data become the single source of truth. So, when we trigger an event, It is going to be shared with ourselves and with other services. This would be a form of event-sourcing where the state of our own service effectively becomes a read model and each event is a write model.
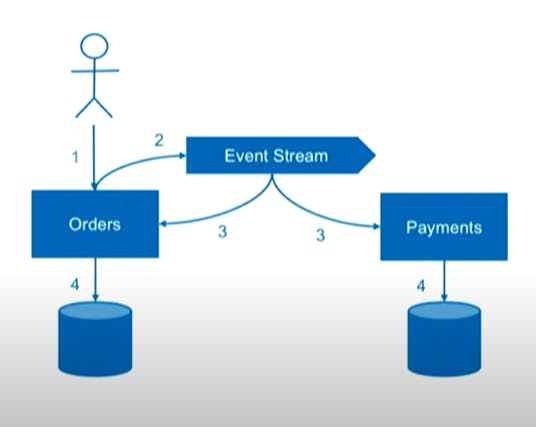
The challenges of this approach is something like product availability in Amazon.com. What if two instances concurrently receive an order of the same item? Both will concurrently check the inventory in a read model and emit an order event. Without some sort of covering scenario, we could run into troubles.
The usual way to handle these cases is optimistic concurrency: to place a read model version into the event and ignore it on the consumer side if the read model was already updated on the consumer side. The other solution would be using pessimistic concurrency control, such as creating a lock for an item while we check its availability.
Event-first approach is hard to implement in scenarios when linearizability is required or in scenarios with many data constraints such as uniqueness checks. But it really shines in other scenarios.
PermalinkConclusion
Microservices architecture has great features such as high availability, scalability, automation, autonomous teams etc. A number of changes in traditional methods are required to obtain maximum efficiency of the microservice architectural style. Data and consistency management is one of the aspects that needs to be designed carefully.
Have a nice productive day :)
PermalinkReference
- O’Reilly, Monolith to Microservices by Sam Newman oreilly.com/library/view/monolith-to-micros..
- Chris Richardson. Using Saga Patterns to Maintain Data Consistency in a Microservice Architecture. youtube.com/watch?v=YPbGW3Fnmbc
- jepsen.io/consistency/models/linearizable
- en.wikipedia.org/wiki/Eventual_consistency
- youtube.com/watch?v=-36j_DGXEwE
- youtube.com/watch?v=CFdPDfXy6Y0&t=461s
- youtube.com/watch?v=LAsMrghdFP0&t=855s
- youtube.com/watch?v=m4q7VkgDWrM